
Introduction to Goldsky’s Platform
Goldsky has developed an innovative platform designed for the real-time processing of blockchain data. It provides a seamless solution for clients to integrate blockchain data into their databases, enhancing product features without the complexity of managing a data pipeline infrastructure. This breakthrough allows developers, especially those engaged in building decentralized applications (dApps) who may not have a background in data engineering, to leverage cutting-edge technologies without deep knowledge of systems like Apache Kafka or Apache Flink.
The Event-Driven Architecture (EDA) Explained
The Goldsky platform is underpinned by an event-driven architecture that incorporates tools such as Apache Flink, Redpanda, Kubernetes, and various cloud services. Yaroslav Tkachenko, a principal software engineer at Goldsky, sheds light on the transformation within the industry. The shift towards utilizing data platforms for customer-facing features rather than just internal analytics signifies a new era where data pipelines that supported reporting are now enhancing web application functionality.
Architecture Overview: Control and Data Planes
Складна архітектура платформи Goldsky розділена на два основні компоненти: площину керування та площину даних.
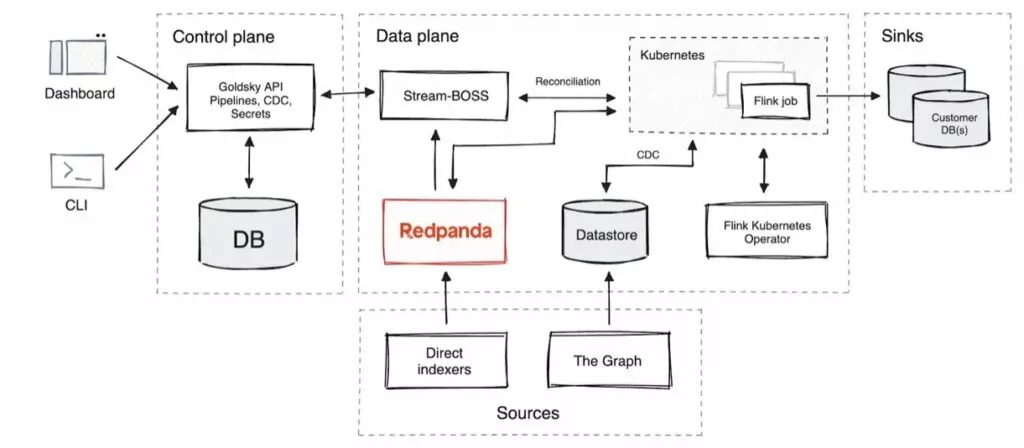
The Control Plane
The control plane’s key responsibility is to manage the configuration APIs. This involves setting up and managing data processing pipelines, which include blockchain data sources and client database sinks. The control plane allows clients to manage configurations using UI and CLI applications, streamlining the process of customizing pipelines according to specific requirements.
The Data Plane
On the other side, the data plane is where the action happens. It takes care of executing the data pipelines configured by the control plane. The raw data is extracted from blockchain sources, transformed accurately, and subsequently inserted into client databases.
Goldsky has implemented two primary methods for extracting data:
Direct Indexing
Direct indexing utilizes the Ethereum ETL project to connect directly to blockchain nodes, extracting fundamental data such as logs and transactions.
Subgraphs
Subgraphs involve processing event telemetry for smart contracts with simple TypeScript applications, providing a more targeted data extraction approach.
Redpanda and Data Transformation
Goldsky’s use of Redpanda, a Kafka-compatible messaging system, has significantly optimized the direct indexing process. Redpanda is integral for messaging and data storage, with S3-compatible tiered storage solutions enabling extended data retention in a cost-effective manner.
The transformation layer is powered by Flink SQL, offering clients the ability to define custom SQL transformations. These transformations are key for filtering, joining, and aggregating data. Flink jobs are run on Kubernetes facilitated by the Flink Kubernetes Operator.
Sink Flexibility and Advantages
Clients have the liberty to choose from an array of pipeline sink types such as PostgreSQL, S3, ElasticSearch, ClickHouse, Rockset, and Apache Kafka. This flexibility ensures that clients can integrate the platform into their existing systems with minimal friction.
The Future of Blockchain Data Streaming
Tkachenko highlights the inherent advantages of data streaming for blockchain technology. The platform’s ability to address complex challenges like blockchain reorgs exemplifies its robustness. By framing these challenges within the context of stream-processing issues, the platform can support advanced applications such as enriching on-chain data with off-chain data, calculating aggregations reliably, and merging data from various blockchains.
Conclusion
Goldsky’s streaming-first architecture is setting a new standard in the processing of blockchain data. It provides the tools and flexibility necessary for companies to drive innovation in the realm of blockchain applications, simplifying the intricate processes of data extraction and transformation, and ensuring that real-time data processing is more accessible than ever before.